135.28 MB
详情
 PiFlow(大数据流水线系统) V0.9 官方版
PiFlow(大数据流水线系统) V0.9 官方版
软件类型:办公管理
软件大小:301.98 MB
更新时间:2021-12-27
软件评级:
运行环境:WinAll
软件语言:简体中文
安全监测:
 无插件
无插件
 360 √
360 √
 腾讯 √
腾讯 √
 金山 √
金山 √
 瑞星 √
瑞星 √
无插件
软件介绍
下载地址
其他版本
PiFlow是一款非常强大的大数据流水线系统,混合型科学大数据流水线系统,这款系统将数据采集、储存的等环节封装成组件,软件简单使用容易,提供100+的数据处理组件,如果有需要朋友的可以来本站下载试试。
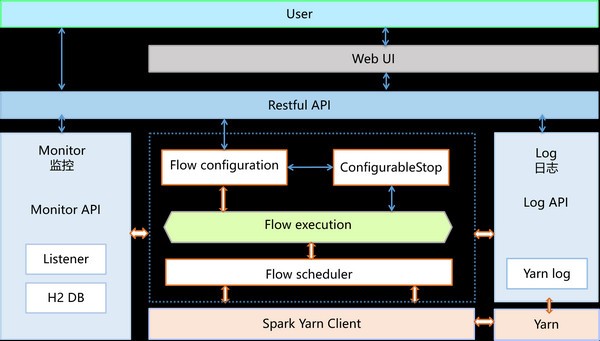
软件特色
简单易用。
可视化配置流水线。
监控流水线。
查看流水线日志。
检查点功能。
扩展性强:
支持自定义开发数据处理组件。
性能优越:
基于分布式计算引擎Spark开发。
功能强大:
提供100+的数据处理组件。
包括Hadoop 、Spark、MLlib、Hive、Solr、Redis、MemCache、ElasticSearch、JDBC、MongoDB、HTTP、FTP、XML、CSV、JSON等。
集成了微生物领域的相关算法。
使用方法
解压piflow-server-v0.9.tar.gz。
tar -zxvf piflow-server-v0.9.tar.gz。
编辑配置文件config.properties。
运行、停止、重启PiFlow Server。
start.sh、stop.sh、 restart.sh、 status.sh。
测试 PiFlow Server。
设置环境变量 PIFLOW_HOME。
vim /etc/profile。
export PIFLOW_HOME=/yourPiflowPath/bin。
export PATH=PATH:PIFLOW_HOME/bin。
运行如下命令。
piflow flow start example/mockDataFlow.json。
piflow flow stop appID。
piflow flow info appID。
piflow flow log appID。
piflow flowGroup start example/mockDataGroup.json。
piflow flowGroup stop groupId。
piflow flowGroup info groupId。
如何配置config.properties。
#spark and yarn config。
spark.master=yarn。
spark.deploy.mode=cluster。
#hdfs default file system。
fs.defaultFS=hdfs://10.0.86.191:9000。
#yarn resourcemanager.hostname。
yarn.resourcemanager.hostname=10.0.86.191。
#if you want to use hive, set hive metastore uris。
#hive.metastore.uris=thrift://10.0.88.71:9083。
#show data in log, set 0 if you do not want to show data in logs。
data.show=10。
#server port
server.port=8002
#h2db port
h2.port=50002
下载地址
正在读取下载地址...
热门软件
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10

沙漏验机 V5.2.2 官方安装版
Atmel Studio7 V7.0.1931 绿色免费版
733.67 MB
详情
EZPlayer V1.5.0 官方安装版
28.38 MB
详情
Adobe Shockwave Player(多媒体播放器) V12.3.5.205 多国语言版
14.39 MB
详情
秋天图片批量剪辑工具 V1.0 绿色中文版
20.47 MB
详情
大白管家 V3.2 官方版
101.27 MB
详情
DolphinScheduler(工作流任务调度系统) V1.3.4 官方版
3.35 MB
详情
游聚游戏平台 V0.7.25 官方最新版
75.23 MB
详情
IP MASS Ping(测试网络状态性能) V1.3 绿色版
240 KB
详情
Easy Sysprep(XP系统封装工具) V4.5.31.611 绿色版
34.06 MB
详情
装机必备 更多+
大家都在看






